The CLARIN service center of the Zentrum Sprache at the BBAW
The CLARIN service center
of the Zentrum Sprache at the BBAW
The CLARIN service center of the Zentrum Sprache at the BBAW
Preservation Policy
Purpose of this document
This document specifies the preservation policy of the institutional repository in its CLARIN center at the BBAW. In case of questions please contact our helpdesk.
Description of the digital archive / Content Scope
From our mission statement:
"The mission of this repository is to ensure the availability and long-term data preservation of German historical and contemporary text corpora, and lexical resources provided by the Zentrum Sprache (Language Centre) at the Berlin-Brandenburg Academy of Science and Humanities (BBAW). It may also serve as a depositing solution for data created by projects external to the BBAW as long as they are freely licensed (e.g. under a Creative Commons type license) and fit well into the portfolio of BBAW research interest."
Preservation Model
We undertake to preserve datasets posted to the repository for the long-term. For this, we rely on our institution (Berlin-Brandenburg Academy of Sciences and Humanities) and on our membership in CLARIN.
The following technical measures ensure the availability of the data for the long-term:
Cooperation Partners
With regards to content, our cooperation partners are listed here.
Data Integrity
To ensure non-corruption of the data, data is always validated by XML tools before ingestion. The integrity of the data is ensured by the version control mechanism in the Fedora-Commons back-end by MD5 checksums.
Our software workflow allows to ingest data only if metadata (in CMDI and DC format) also is present.
Roles and Responsibilities
A contract is concluded in conjunction with the data transfer. All scientific primary data as well as the associated metadata in this repository are licensed under CC-BY-SA except when a different license is stated.
Access / Use
Please follow our Terms of Use.
Data formats
To ensure compatibility and interoperability among the resource we provide, all primary data is encoded in widely accepted data representation standards such as the DTA Base format for historical texts (a subset of TEI P5 developed by the project Deutsches Textarchiv). The DTA Base format and via this format much of TEI P5 can be transformed into TCF, the CLARIN-D internal pivot format for textual data. An LMF based XML serialization (Lexical markup format) and TEI P5 based dictionary models are used for lexical data. All metadata is encoded in the CMDI format, the CLARIN specific component metadata model. Read more about CLARIN specific data formats in the CLARIN-D User guide. The staff at our CLARIN-D centre will provide additional support in resource curation and conversion.
Searching and harvesting
The metadata of the resources provided by this repository are exposed by an OAI-PMH conforming endpoint for automatic querying and harvesting. An aggregated view at all CLARIN resources and tools is available via the faceted search interface of the Virtual Language Observatory. You can also search directly in the repository of the BBAW based CLARIN-D centre.
Quality management
This repository has been certified by the Core Trust Seal consortium. Resources are admitted to the repository only after previous quality control of the corresponding data and metadata.
The assessment is based on the DFGRules of Good Scientific Practice, the European Code of Conduct for Research Integrity of the ALLEA (All European Academies) association, the "BBAW-Richtlinien zur Sicherung guter wissenschaftlicher Praxis" (BBAW Guidelines for Ensuring Good Scientific Practice) as well as the best-practice guidelines of CLARIN-D as described in the CLARIN-D User Guide.
Methods for quality assurance form a substantial part of the data production workflows applied by the CLARIN service center at the BBAW. These include e.g. the collaborative web-based curation tool DTAQ as well as additional methods.
Data management
We ensure permanently valid references for data and metadata by associating persistent identifiers (PIDs) with all data sets. New versions of data sets are provided with separate PIDs, while the old versions remain available via their original PID. Data integrity is achieved by checking MD5 hash values of the datasets at least once a year. Likewise at least once a year we check whether metadata needs to be updated or whether outdated file formats need to be converted. The repository data is backed-up weekly to a tape drive. When ingesting new data, snapshots of the relevant virtual servers are taken in order to allow for fast disaster recovery from scratch in case of a total system failure.
We use Fedora Commons as our repository software.
A contract is concluded in conjunction with the data transfer.
Workflow
Storage Procedures
The virtual machines used by the BBAW CLARIN center repository reside on hard disk space secured by RAID level 6. Every night filesystem and database dumps of the virtual machines are copied to a dedicated backup server system (also RAID level 6).
Deterioration of disk media is checked by S.M.A.R.T. status checks. Weekly backups to a LTO-8 tape library are performed. Backup tapes are deposited in a locked safe in a separate fire safety zone of the building. Each year one additional full backup tape set is separated and added to a long term archive.
The backup software (Bareos) internally makes use of checksums to recognize tape block errors and tape media deterioration.
The virtual machines disk images are dumped and replicated to a secondary virtualization server in a different server room in a different fire safety zone. In case of a system failure, these replicated disk images can be manually started within minutes.
An overview of the storage locations and media used can be found here.
go to the search interface
Purpose of this document
This document specifies the preservation policy of the institutional repository in its CLARIN center at the BBAW. In case of questions please contact our helpdesk.
Description of the digital archive / Content Scope
From our mission statement:
"The mission of this repository is to ensure the availability and long-term data preservation of German historical and contemporary text corpora, and lexical resources provided by the Zentrum Sprache (Language Centre) at the Berlin-Brandenburg Academy of Science and Humanities (BBAW). It may also serve as a depositing solution for data created by projects external to the BBAW as long as they are freely licensed (e.g. under a Creative Commons type license) and fit well into the portfolio of BBAW research interest."
Preservation Model
We undertake to preserve datasets posted to the repository for the long-term. For this, we rely on our institution (Berlin-Brandenburg Academy of Sciences and Humanities) and on our membership in CLARIN.
The following technical measures ensure the availability of the data for the long-term:
- the use of future-proof open standards like XML files
- continuous format conversion (e.g. TEI XML P4 to P5 or CMDI metadata 1.1 to 1.2)
- keeping all versions of data and metadata to avoid information loss
- refreshing storage and backup media at regular intervals (e.g. hard disks on SMART errors or every 5 years, tape media at least every 50 writes)
Cooperation Partners
With regards to content, our cooperation partners are listed here.
Data Integrity
To ensure non-corruption of the data, data is always validated by XML tools before ingestion. The integrity of the data is ensured by the version control mechanism in the Fedora-Commons back-end by MD5 checksums.
Our software workflow allows to ingest data only if metadata (in CMDI and DC format) also is present.
Roles and Responsibilities
A contract is concluded in conjunction with the data transfer. All scientific primary data as well as the associated metadata in this repository are licensed under CC-BY-SA except when a different license is stated.
Access / Use
Please follow our Terms of Use.
Data formats
To ensure compatibility and interoperability among the resource we provide, all primary data is encoded in widely accepted data representation standards such as the DTA Base format for historical texts (a subset of TEI P5 developed by the project Deutsches Textarchiv). The DTA Base format and via this format much of TEI P5 can be transformed into TCF, the CLARIN-D internal pivot format for textual data. An LMF based XML serialization (Lexical markup format) and TEI P5 based dictionary models are used for lexical data. All metadata is encoded in the CMDI format, the CLARIN specific component metadata model. Read more about CLARIN specific data formats in the CLARIN-D User guide. The staff at our CLARIN-D centre will provide additional support in resource curation and conversion.
Searching and harvesting
The metadata of the resources provided by this repository are exposed by an OAI-PMH conforming endpoint for automatic querying and harvesting. An aggregated view at all CLARIN resources and tools is available via the faceted search interface of the Virtual Language Observatory. You can also search directly in the repository of the BBAW based CLARIN-D centre.
Quality management
This repository has been certified by the Core Trust Seal consortium. Resources are admitted to the repository only after previous quality control of the corresponding data and metadata.
The assessment is based on the DFGRules of Good Scientific Practice, the European Code of Conduct for Research Integrity of the ALLEA (All European Academies) association, the "BBAW-Richtlinien zur Sicherung guter wissenschaftlicher Praxis" (BBAW Guidelines for Ensuring Good Scientific Practice) as well as the best-practice guidelines of CLARIN-D as described in the CLARIN-D User Guide.
Methods for quality assurance form a substantial part of the data production workflows applied by the CLARIN service center at the BBAW. These include e.g. the collaborative web-based curation tool DTAQ as well as additional methods.
Data management
We ensure permanently valid references for data and metadata by associating persistent identifiers (PIDs) with all data sets. New versions of data sets are provided with separate PIDs, while the old versions remain available via their original PID. Data integrity is achieved by checking MD5 hash values of the datasets at least once a year. Likewise at least once a year we check whether metadata needs to be updated or whether outdated file formats need to be converted. The repository data is backed-up weekly to a tape drive. When ingesting new data, snapshots of the relevant virtual servers are taken in order to allow for fast disaster recovery from scratch in case of a total system failure.
We use Fedora Commons as our repository software.
A contract is concluded in conjunction with the data transfer.
Workflow
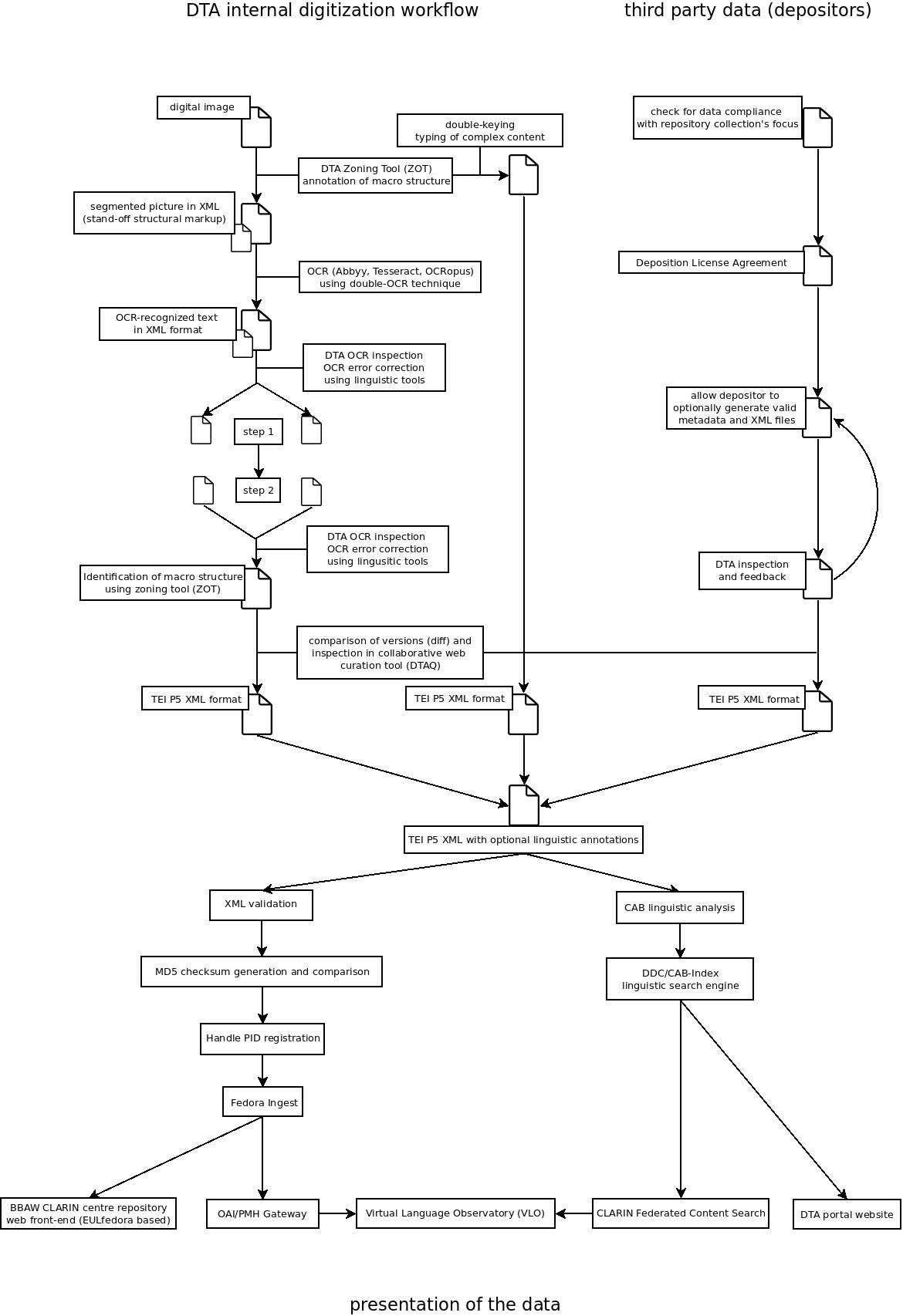
Storage Procedures
The virtual machines used by the BBAW CLARIN center repository reside on hard disk space secured by RAID level 6. Every night filesystem and database dumps of the virtual machines are copied to a dedicated backup server system (also RAID level 6).
Deterioration of disk media is checked by S.M.A.R.T. status checks. Weekly backups to a LTO-8 tape library are performed. Backup tapes are deposited in a locked safe in a separate fire safety zone of the building. Each year one additional full backup tape set is separated and added to a long term archive.
The backup software (Bareos) internally makes use of checksums to recognize tape block errors and tape media deterioration.
The virtual machines disk images are dumped and replicated to a secondary virtualization server in a different server room in a different fire safety zone. In case of a system failure, these replicated disk images can be manually started within minutes.
An overview of the storage locations and media used can be found here.
go to the search interface